(블로그를 이전했습니다.
이 글을 포함해 더 많은 컨텐츠에 관심이 있으시다면 링크를 따라가주세요.
This blog has been moved. Please follow this link if you are interested in more contents including the one you are about to read now.)
현대적인 딥러닝 모델을 디자인할 때 거의 항상 빠지지 않고 쓰이는 테크닉들이 있다. 하나는 recurrent 구조 (LSTM, Attention)이고 다른 하나는 batch normalization (BatchNorm)이다. LSTM과 attention에 대해서는 recurrent neural net을 다루면서 자세히 살펴보도록 하고 이번 글에서는 학습 과정에서 뉴럴넷을 안정시켜주는 표준화 기법 중 하나인 batch normalization에 대해 다뤄보겠다.
- 기존 방법의 문제점
- BatchNorm
- 알고리즘
- 테스트할 때
- BN layer
- TensorFlow 구현
기존 방법의 문제점
BatchNorm이 어떤 의미를 가지는지를 알기 위해서는 BatchNorm이 고안되기 이전의 딥러닝 모형 초기화 및 학습 과정 표준화 과정을 둘러볼 필요가 있다.
뉴럴넷이 안정적으로 잘 학습되기 위해서는 입력층에 넣을 인풋과 각 층의 weight를 표준화할 필요가 있다. BatchNorm이 고안되기 전에는 두 가지 방법을 주로 사용했는데, 이전 포스트[1, 2]에서 각각의 방법을 간단히 다룬 바 있다. 간단히 복기하자면 이렇다: (1) 인풋은 centering과 scaling하고 (2) 인풋 뉴런 

여기서 중요한 문제가 발생한다. 입력층에 넣는 인풋은 표준화할 수 있다. 뉴럴넷에 넣기 전에 우리가 원하는 방식으로 원하는 만큼 preprocessing을 하면 된다. 그 결과 입력층의 input distribution은 항상 비슷한 형태로 유지가 되고 안정적으로 가중치 학습을 진행할 수 있다.

그러나 은닉층은 인풋의 분포가 학습이 진행됨에 따라 계속 변한다. 은닉층은 이전 레이어의 activation 

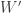
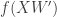
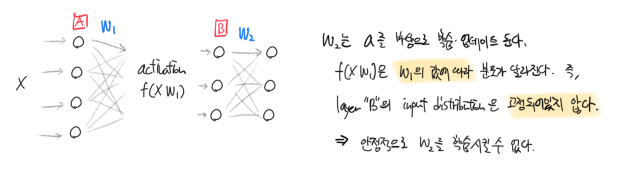
Batch Normalization
알고리즘
바로 위에서 언급한 문제를 internal covariate shift라고 한다. 말 그대로 입력층보다 깊은, 즉 내부에 있는(internal) 층의 입력값, 즉 공변량(covariate)이 고정된 분포를 갖지 않고 이리저리 움직인다(shift)는 의미이다. BatchNorm은 바로 internal covariate shift를 해결하는 테크닉이다.
[1]
은닉층의 입력도 표준화한다면 안정적으로 깊은 레이어의 가중치도 학습시킬 수 있을 것이다. “은닉층의 입력을 표준화한다“는 것은 곧 “이전 층의 출력(raw activation)을 표준화한다“는 의미와 같다.
딥러닝은 거의 항상 전체 샘플을 mini batch로 나누어 학습하고 가중치를 업데이트하므로 이전 층의 raw activation을 표준화할때도 각 batch마다 따로 표준화하면 된다.

이와 같이 각각의 minibatch의 평균 

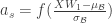
쉬워도 너무 쉽다. 이렇게만 하면 될 것 같지만..
[1의 문제점]
문제가 몇 가지 있다. 이렇게 은닉층의 입력을 표준화하면 gradient update 과정에서 bias(편향)값이 무시된다. [1]만을 사용해서 표준화한다고 할 때 그라디언트 업데이트 과정을 자세히 살펴보자. Raw activation을 
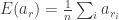
- 그라디언트를 계산한다.
, where
is a loss function.
- 편향(과 가중치)을 업데이트한다.
- 편향을 업데이트한 이후의 raw activation은:
- [1]을 이용해서 센터링만 한 raw activation은:


![\begin{array}{lcl} a_{r_{centered}} ^\prime &=& a_r ^\prime - E(a_r ^\prime) \\ &=& \{(wx + b) + \Delta b\} - \{ E[wx + b] + \Delta b \} \\ &=& (wx + b) - E[wx + b] \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Blcl%7D+a_%7Br_%7Bcentered%7D%7D+%5E%5Cprime+%26%3D%26+a_r+%5E%5Cprime+-+E%28a_r+%5E%5Cprime%29+%5C%5C+%26%3D%26+%5C%7B%28wx+%2B+b%29+%2B+%5CDelta+b%5C%7D+-+%5C%7B+E%5Bwx+%2B+b%5D+%2B+%5CDelta+b+%5C%7D+%5C%5C+%26%3D%26+%28wx+%2B+b%29+-+E%5Bwx+%2B+b%5D+%5Cend%7Barray%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Bias 


이 때문에
또 다른 문제도 있다. raw activation의 분포를 고정시키는 것은 좋지만 항상 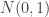
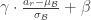
이 형태의 activation을 사용할 경우 필요하다면 표준화를 되돌릴 수도 있다. 
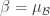
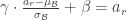
[2]
위의 문제를 극복하기 위해 표준화한 후 scaling 및 shifting 한 raw activation, 즉

를 activation function 



BatchNorm엔 장점이 꽤나 많은데
- bias 업데이트를 무시하지 않는다.
- 은닉층마다 적절한 input distribution을 가질 수 있다. scaling factor
- 필요한 경우 표준화를 하지 않을 수도 있다. 위에서 언급한
- Activation 값을 적당한 크기로 유지하기 때문에 vanishing gradient 현상을 어느정도 막아준다. 덕분에 tanh, softmax같은 saturating nonlinearity를 사용해도 문제가 덜 생긴다.
- batch-wise로 계산하기 때문에 컴퓨팅하기 용이하다.
- 위의 장점들을 모두 가지면서, 동시에 각 층마다 입력 분포를 특정 형태로 안정시켜서 internal covariate shift를 방지할 수 있다.
- 입력 분포가 안정되므로 학습시 손실함수가 더 빨리, 더 좋은 값으로 수렴한다.
- 초기 learning rate를 크게 설정해도 안정적으로 수렴한다고 한다.
- Weak regularizer로도 작용한다고 한다.
이쯤 되면 거의 만능이다.
테스트할 때
지금까지 다룬 내용은 모두 학습 과정에서 일어나는 일들이다. 학습 과정에서는 raw activation을 minibatch mean, stdev로 표준화하면 됐었다. 그런데 학습을 마치고 테스트(또는 evaluation, inference)를 할 때에는 minibatch mean, stdev가 존재하지 않는다.
테스트 과정에서는 대신 전체 training data의 mean, stdev를 사용해서 BatchNorm을 한다. 이 때 전체 training data의 mean, stdev를 한 번에 계산하기에는 메모리의 제약이 있으므로, minibatch statistic을 평균낸 값을 대신 사용한다.
즉,
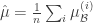
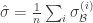
Minibatch statistic을 따로 저장할 필요 없이 학습 과정에서 moving average로 

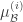


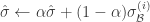
BatchNorm layer
ReLU activation을 뉴럴넷의 레이어로 나타낼 수 있듯 BatchNorm 또한 레이어로 표현할 수 있다. BN layer는 raw activation과 activation function 사이에 위치한다. Convolutional layer에 BatchNorm을 적용하고 싶을 때에도 동일하게 raw feature map과 ReLU layer 사이에 BN layer를 추가하면 된다.

BN layer는 mini batch의 raw activations 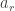

또한 테스트 때 사용하기 위해 학습 과정에서 minibatch statistic의 exponential moving average(또는 그냥 MA)를 매 minibatch마다 업데이트한다.
TensorFlow 구현
구글에서 고안한 방법답게 TensorFlow에 이 내용들이 친절히 함수로 구현되어 있다. tf.nn.batch_normalization, tf.contrib.slim.batch_norm를 쓰면 간단히 위 알고리즘을 모형 구축에 사용할 수 있다.
tf.nn.batch_normalization을 사용할 경우, minibatch statistic의 EMA를 계산하는 코드를 따로 작성해야 한다.
tf.contrib.slim.batch_norm를 사용할 경우 is_training 옵션을 True로 주면 자동으로 EMA를 계산해서 저장하고, False로 주면 저장된 EMA 값으로 activation을 표준화한다.
TF-Slim 레이어에도 쉽게 적용시킬 수 있다.
import tensorflow as tf import tensorflow.contrib.slim as slim bn_params = {"decay": .9, "updates_collections": None, "is_training": tf.placeholder(tf.bool)} net = slim.fully_connected(input, 1024, normalizer_fn=slim.batch_norm, normalizer_params=bn_params)Convolutional layer에도 마찬가지다.
net = slim.conv2d(input, 64, [5,5], padding="SAME", normalizer_fn=slim.batch_norm, normalizer_params=bn_params)참고
- Ioffe and Szegedy, 2015, “Batch normlization: Accelerating deep network training by reducing internal covariate shift”
- TensorFlow API

큰 도움이 되었습니다
상세한 포스팅 정말 감사드립니다 :D
좋아요좋아요
Exponential moving average부분에서 질문이 있는데요.
그렇다면 batch size가 32라고 할 때 처음에 u hat이 1~32번의 instance의 평균으로 계산이 되고 이후에 33~64번 instance 가 학습되고 난 후에 u hat은 1~32번의 평균이 ub로, 33번~64번의 평균이 u hat값이 되어 최종 u hat이 alpha(u hat) + (1-alpha)(ub) 이렇게 되는 건가요?
좋아요좋아요
https://www.investopedia.com/ask/answers/122314/what-exponential-moving-average-ema-formula-and-how-ema-calculated.asp
여기 보면 10 day EMA를 계산할 경우 1~10일, 2~11일 값을 이용해서 2번째? EMA를 계산하는데 batch normalization에서도 동일한지 궁금합니다.
그러니까 1~32번, 2~33번 이렇게 되는건지 아니면 1~32, 33~64 이렇게 되는 건지요. 만약 후자라면 위의 예제에서 10일의 기간은 BN에서 뭐가 되는 건지 궁금합니다.
좋아요좋아요
친절한 설명 감사합니다~
좋아요좋아요
inference 과정에서 variance가 unbiased 하지 않습니다. m/(m-1)을 곱해야 할 거 같습니다.
좋아요좋아요
감동…. 교수급 설명이었습니다.
좋아요좋아요